(论文阅读)IMPRESS:基于重要性指导的 LLM 多级 KV 存储系统
什么是 KV Cache
LLM 推断主要可以划分为 Prefill 和 Decode 两个阶段。 Prefill 阶段,模型处理输入的全部 Prompt,并进行前向计算。这个阶段的目的是生成第一个输出token,即响应的起始点。在这个阶段,模型可以复用具有相同前缀的 Prompt 生成的 K、V 向量。Prefill 完成后,模型进入 Decode 阶段,逐个生成剩余的响应token。在 Decode 阶段,生成的 Token 逐个拼接到当前输出序列的末尾,调用 Decoder 输出下一个 Token。 Prefill 和 Decode 阶段,序列 Token 的 K、V 也可以被不断复用。总而言之,在同一个窗口中,具有相同前缀的不同序列可以共享前缀部分的 K、V 向量,减少 GPU 计算量。
IMPRESS
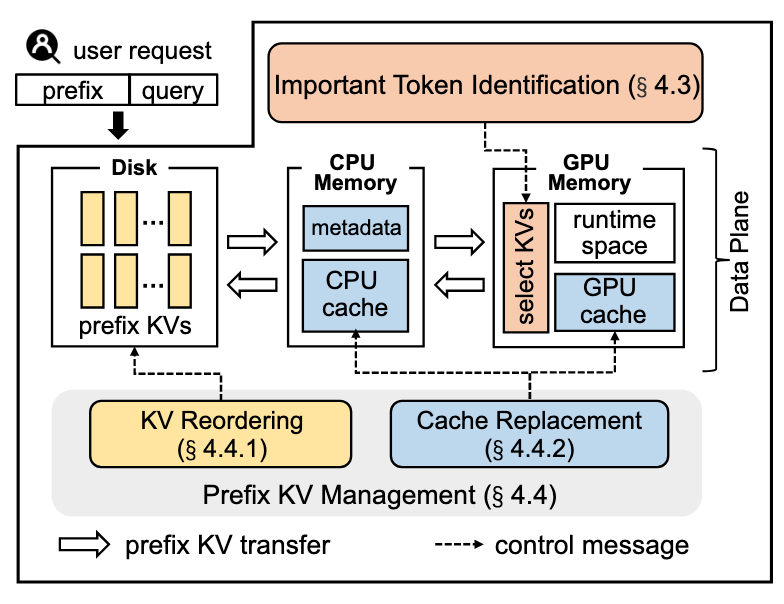
该工作刚刚发表于 FAST'25,通过对 LLM 推理中 KV Cache 的优化来提升运行效率。目标是解决现有系统在管理海量 KV 数据时的 I/O 效率低下问题,减少 LLM 首 Token 推理的延迟(Time to First Token,TTFT),也即我们常说的 Prefill 优化。IMPRESS 基于重要性指导(Importance-Informed)的方法,设计了多级存储(GPU RAM <-> CPU RAM <-> SSD)下的 KV Cache。核心贡献点:
- 提出了多级 Prefix KV Cache 系统 IMPRESS,在重要 Token 识别的基础上,充分利用 GPU RAM、CPU RAM 及 SSD 的特点对 LLM 推理过程中产生的 KV 进行缓存。
- 设计了一种基于重要性指导的关键 Token 识别方法,有效减少 I/O 数据传输量。
- 提出了重要性感知的 KV 管理策略,包括 KV Chunk 重组织与新的评分驱动缓存管理策略,进一步优化存储过程。
要解决什么问题?
在多头注意力(Multi-head Attention, MHA) 中,Multi-head 指的是一个注意力机制可以被分为多个"头"(heads),这些头是独立执行注意力计算的子模块。每个头对输入数据执行相同的注意力计算流程,但它们拥有不同的权重矩阵,从而能够从输入中关注不同的特征子空间。这些头对推理效果的影响可能不同,我们可以从这些头中选择少数几个用作代表,来完成对重要信息的快速判断,例如,可以通过这些头识别出哪些 Token 对推理效果至关重要。(本文中,被选择的 Head 被称为 Probe Head,中文为探查头)
本文要解决的核心问题是:
- 如何降低 KV Cache 本身的 I/O 开销?
- 如何对 Token 进行重要性识别,避免对不重要 Token 的访问?
重要 Token 识别
对于如何识别重要 Token,本文有两个重要的 Observation
作者观察到大语言模型中的 MHA 从同一个输入序列生成多个独立的头,但这些头对于重要 Token(即对注意力权重影响较大的词元)的选择高度相似。
- 每个注意力头都会计算自己视角下的 KV 向量。
- 尽管不同头对应的权重矩阵不同,但它们共享同一序列的数据,因此在识别重要 Token 时结果趋于一致。
作者进一步发现,不仅不同头在同一层存在高相似性,重要 Token 集的相似性在不同采样比例和不同规模的大语言模型(OPT-6.7B、OPT-13B、OPT-30B)中都保持稳定。 根据上述观察,本文设计了如下重要 Token 识别方法:
(1) 探查头的重要性计算
- 在 Transformer 每一层的多头注意力机制中,选取少量探查头进行计算。
- 例如,对于某层的 32 个注意力头,选取 h1,h2,h3 (即前三个头)作为探查头。这么做的原因来自 Observation 1, 同一层中所有的头在识别重要 Token 时结果趋于一致。
- 每个探查头会计算它所负责的部分注意力权重(Attention Score),并根据权重筛选出重要 Token 集(注意力权重在 top X% 的 Token 被认为是重要的,X 这个值是可调的)。
(2) 探查头之间相似性分析
计算所有探查头的结果相似性:
- 若探查头之间的重要 Token 集具有高度相似性(Jaccard 相似度达到某个设定阈值),则认为重要 Token 的选择结果具有一致性。
- 如果结果不一致(相似度低于阈值),则回退到加载完整多头 KV 数据的方式,确保推理精度。
(3) 重要 Token 的最终筛选
- 根据探查头识别的结果,生成重要 Token 集并进行 KV 数据选择性加载:
- 重要 Token 的 KV 数据会被加载至 GPU 内存,用于进一步推理计算。
- 非重要 Token 的 KV 数据会被跳过,显著减少 I/O 数据量。
基于重要性指导的 KV 管理
接着,根据计算的 Token 重要性,为 KV 数据分配一个重要性评分。数据评分越高,其加载优先级越高,应该存储在更为高速的设备上。
KV Reordering
提出一种基于重要性的 KV 重排序方法,通过周期性地对存储设备上的 KV 数据进行组织,使得重要 KV 被打包到更密集的存储块中,减少加载操作所需的数据量。这一做法的出发点是 重要的 Token 一般会被集中访问。
具体实现步骤如下:
- 数据分析:通过计算注意力权重对 KV 的重要性进行量化,并对每个 Token 的 KV 数据分配一个重要性评分。
- 重要性引导的重排序:定期(例如每10分钟一次)重新组织存储在磁盘上的 KV块,尽量将同一前缀中的高分 KV 数据聚合到同一个 chunk 中;不重要的 KV 数据则被分离,存储在其它独立的 chunk 中。
- 异步操作:为了避免重排序影响推理的实时性能,这一过程与 LLM 推理异步进行。
基于评分的多级 KV 存储
前文的设计中,IMPRESS 倾向于加载重要性高的 Token 的 KV 数据。根据这一点,本文不再使用传统的缓存数据结构和替换策略,而是基于 访问频率和前文中的 Token 重要性打分,在该分数基础上进行替换: Score = Access Frequency × Importance Ratio 最小堆存储(Min-Heap):
- 为 GPU RAM 和 CPU RAM 分别构建两个最小堆,用于管理缓存内容:
- GPU RAM 最小堆:存储最重要的 KV 数据,并保证评分最低的数据可以降级到 CPU RAM。
- CPU RAM 最小堆:存储次重要的 KV 数据,当 GPU 缓存需要时可以提升高优先级的数据。 当新数据需要加载到 GPU 时,评分最低的 GPU 缓存数据会自动降级到 CPU;同样,在 CPU RAM 中评分最低的数据可以被剔除,降级至磁盘。
实验结果
在 OPT 上的实验显示
- KV Reordering 减少了高达 3.8 倍的磁盘 I/O时间。
- Score-Based Cache Policy 显著提升了缓存命中率,同时减少了总推理时间至 2.8 倍以上。
- 整体推理精度的下降仅为 0.2%,证明了该方法在性能与精度之间实现了较好的平衡。